v3.2.0 版本更新公告
注册登录
【新增】勾选阅读隐私政策协议弹窗提示
数据管理
文件
【优化】阿里云下载流量获取
从阿里云下载日志中获取下载流量,并提供给计费模块,以便计算下载费用。
【优化】添加文件界面显示当前文件夹路径
添加文件时,集群上传默认上传到RawData,其他方式上传时默认默认传至当前文件夹,各个添加文件界面显示当前文件夹路径,分别如下图:
1)网页上传

2)集群上传

3)工具上传

4)项目复制

【优化】系统预制文件夹优化
新建项目时,除了自动生成RawData、ResultData、ManualData等文件夹外,还自动生成ReferenceData文件夹。
【新增】显示文件真实路径
支持查看和复制文件云平台路径及真实路径。如下图:

【新增】支持按标签查询文件夹
支持按文件夹标签检索分析结果文件夹,如下图:

表格
【优化】编辑表格内容时,支持从文件界面选择记录
编辑表格单元格内容时,除了可以输入值外,还能选择文件或文件夹,如下图:


【新增】支持在线新增行
针对已上传的表格,支持在线新增行,如下图:

流程分析
【优化】mini tool在线校验提示
该功能用于创建流程时,用户写入的WDL代码不符合minitool的校验规范时,界面提示报错的条数及具体内容

当出现错误时,界面提示如“1error”,用户点击图标展示详细报错信息,具体到几行几列
同步代码编辑框中突出显示错误代码行
【新增】批量导入工作流支持选择覆盖
该功能用于管理员批量迁移流程
当点击流程管理的【导入】按钮,识别到导入文件有重名工作流时,需用户选择重名文件处理方式:

替换目标工作流,则以导入的文件,覆盖原先项目里已有的工作流,且保留原先的关联关系,可触发公共库的更新发布
跳过并生成副本,参考原有逻辑,在流程分析中添加新的工作流,在重名后自动添加后缀
让我决定每个工作流,选择后可选择指定工作流覆盖

说明:导入覆盖时无法覆盖预制工作流、工具箱配置的工作流及无编辑权限的工作流
【新增】用户自定义结果文件名称及目录
该功能用于运行任务时,修改结果文件夹名称及目录
提交任务时,在第三步”输出设置“中点击【修改输出目录】

任务输出的结果文件夹默认存在/Files/resultdata/workflow下,且默认以“TasklD”命名结果文件夹
Step1可选择修改层级目录,选择层级即表示在层级之下创建结果文件夹
Step2确定结果文件夹名称,修改完成后点击【确认】,任务分析完成后结果文件夹将按用户自定义名称及目录结果保存
当用户未选择修改目录名称,则仍以Taskid命名文件夹
说明:
文件夹名称需同一层级不能重名,重名需提示用户修改
仅支持英文字母、数字、”-“、”_“、”.“
【新增】创建任务备注
该功能用于在创建任务时自定义任务信息,方便用户快速查阅任务
创建任务时,可在“输出设置”输入任务备注信息

任务备注允许输入200字以内的字符
当生成批量任务时,备注对应批量的每条任务
【优化】创建WDL时提供Demo
该功能用于编辑工作流时,展示Demo示例,可展开折叠

交互分析
图像分析
【新增】任务管理页增加图像分析入口
详见“任务管理>>【新增】操作增加图像工具”。
可视化
【新增】兼容蛋白流程数据
支持SAW-PT流程数据的可视化
“图层选择>>分析结果图层”增加“蛋白组”分类
支持多窗口打开图层。且同一个binsize下,在主窗口进行套索/聚类选择时,可联动副窗口展示。

支持在伪彩图模式下,对基因/蛋白MID进行背景噪音过滤,投递流程输出过滤后的gef文件。



高级分析
【优化】任务栏显示用户自定义名称
高级分析运行的任务均可在任务管理【详情-备注】中自定义名称,进行可视化时可显示定义的任务名,以方便区分不同的任务,如不自定义扔显示之前taskid,自定义名称限制字符数=taskid字符数


【优化】时空高级分析内容优化
1、max gene type上限不做限制,默认值为none,用户可自定义过滤数值

2、EN任务报warning,报告也支持可选结果
3、任务栏中任务号可复制查询

4、加载数据界面提示内容优化

【优化】支持青岛及外部用户报告中切片图像抓取
时空高级分析报告中切片图像支持外部用户上传及青岛传输数据进行高级分析产生报告的图像抓取
【优化】报告页面暂存功能
使用相同的任务号生成过的分析报告无需再次点击提交生成,会直接显示报告并显示上次生成时间

个性分析
【新增】支持将个性分析结果数据上传项目「数据管理」
容器启动时将会自动生成 output 目录,可以将需要同步至项目「数据管理」的结果数据拷贝至 output 目录下:

Step1: 启动 Terminal

Step2:使用命令将文件移动或拷贝至 output 目录

示例:
- 将 work 目录下的1.md文件移动至 output 目录,你可以使用以下命令:
mv /data/work/1.md /data/output/
- 将 work 目录下的1.md文件拷贝至 output 目录,你可以使用以下命令:
cp /data/work/1.md /data/output/
Step3: 完成分析并将数据全部转移至 output 目录后关闭容器,output 下的文件将会自动上传到「数据管理」/Files/ResultData/Notebook/{user}/output/{project_id}/目录下

注意
容器关闭时,会自动将 output 目录下的数据上传「数据管理」。挂载数据、重置资源会重启容器,也会触发数据自动上传。
数据保存的状态可以在「任务管理-数据分析」模块查看。

【新增】新增 AI 助手,辅助完成代码编写
新增 AI 官方镜像(仅在阿里云片区上线),选择 stereonote-ai 镜像启动容器即可体验
注意
可将 stereonote-ai 作为基础镜像安装所需软件包,构建带有 AI 助手的自定义镜像,如何基于基础镜像构建自定义镜像,详见基于平台预设基础镜像构建。

stereonote-ai 提供了两种不同的界面交互。在 JupyterLab 中,你可以使用聊天界面进行对话,以帮助处理代码。此外,你还可以使用%%ai魔术命令调用模型。
编程助手
Jupyter 聊天界面如下图所示,用户可以直接与 Jupyternaut(编程助手)进行对话。

简单问答:

代码生成:
直接在对话框输入问题

代码解释:


代码重写:
如果你对代码不满意,还可以要求重写代码:

代码完成了重写:

Notebook 文件生成:
使用/generate命令可以直接生成 notebook:

可以在/data/work 目录下查看 AI 生成的 Notebook 文件:

魔法命令
使用%ai和%%ai作为魔法命令来调用AI模型,需要先加载魔法命令:
%load_ext jupyter_ai_magics
查看使用说明:
%ai help
魔法命令ai的基本语法
%%ai命令允许使用给定的提示,去调用所选择的语言模型。其语法为 provider-id:local-model-id,其中 provider-id 可以理解为是模型提供方,如huggingface、openai,local-model-id 是模型供应商的特定模型。代码块从第二行起就是prompt提示。
DCS智能云平台官方提供的模型为**:stereonote_provider:depl-gpt35t-16k**。调用时需要使用:
%%ai stereonote_provider:depl-gpt35t-16k
代码生成:
我们把format的参数改成 code,选择一道 LeetCode平台上通过率为30.7%的困难题,让 AI 解决。

生成的结果代码如下:

在LeetCode上提交之后直接就通过了。

简单火山图绘制:

生成结果并运行:

代码 debug:
我们找到一段包含五处错误的Python代码:
def calcualte_area(radius):
if type(radius) =! int or type(radius) != float:
return"Error: Radius should be a number.
else:
area = 3.14 * raduis**2
return area
print calcualte_area('5')
让 AI 进行修正并解释原因:

不限于编程:
除了和代码相关的功能之外,AI还可以生成LaTex公式、网页、 SVG图形等内容。
LaTex公式:
我们想让它生成一下伯努利方程组。只要把format的参数改成math,结果就会以LaTex排版之后的格式输出。

网页:
我们让它生成一个登录页面,这里需要把format参数改成html。

SVG 图形:
让 AI 直接生成一些简单图形,以SVG的形式进行展示。

镜像管理
【新增】无需重新构建,即可编辑镜像名称和描述
在镜像构建的任意状态下,可直接点击“编辑”更改镜像的名称、描述及标签,无需从头开始构建


【优化】使用 bash 指令构建镜像时支持空格、空行及带#的注释行
以下 bash 指令可成功构建:
pip install star == 0.1.2
# pip install pip==21.3.1
pip install pip==21.3.1
任务管理
【新增】操作增加图像工具
针对下述流程增加图像分析入口:
T 开头的标准分析任务(在图像投递W版的任务)
R 开头的自动预处理任务(在图像投递W版的任务)
WorkFlow 版本的标准分析任务:SAW-ST-V6/V7
WorkFlow 版本的recut 流程:SAW-ST-V6-recut、SAW-ST-V7-recut
WorkFlow 版本的count 流程:SAW-ST-V6-count、SAW-ST-V7-count
WorkFlow 版本的registration:SAW-ST-V7-registration、SAW-ST-V7-registration

图像分析各模块支持的数据输入类型如下:
拼接:可支持的数据为小图(ipr的元信息:StitchedImage=false)
校准:可支持的数据为染色类型为 DAPI&mIF 的数据。(ipr的元信息:染色类型=DAPI/MIF)

组织分割和细胞分割:不做限制,均支持。
【新增】官方流程任务增加官方标记
当任务运行的流程为官方流程时,任务新增“STO”标记

【新增】备注修改、搜索
该功能用于展示用户在提交任务时自定义的备注信息
任务管理新增一列显示提交任务时生成的任务备注,默认显示在列表中
进入详情页可以查看备注,创建者支持修改备注
3、搜索栏新增备注条件搜索
Genpilot
【新增】助手头像支持AI生成
助手中心创建/编辑助手时,支持由AI生成助手头像。每个用户每24小时限制生成10张头像。
- 选择:AI生成头像

- 描述头像需求

- 调整、应用头像

【新增】增加文献订阅功能
支持按条件查询、导出、订阅文献。
首页按订阅条件展示IF最高的10篇文献。如无订阅,展示最新的10篇时空单细胞文献。单击按钮可进入文献订阅:

订阅页面:

(1)查询及订阅条件
是否有pdf:文献是否有对应的pdf文件
语言选择:Genpilot底层将文献原文翻译成中文、英文,默认选择英文库。
英文库:文献全部为英文。物种、组织、疾病三个条件需输入英文进行查询,输入中文将无法查到文献。下载的文献内容也将以英文显示。
中文库:文献全部为中文。物种、组织、疾病三个条件需输入中文进行查询,输入英文将无法查到文献。下载的文献内容也将以中文显示。
文献领域:包括时空、单细胞、时空单细胞,默认全选。
- 单细胞:文章标题或摘要中符合以下任一条件:
包含"single cell"或"single-cell" 和 "transcri"或"protein"
- 包含"scrna"
时空:文章标题或摘要中包含"spatial"或"transcri"
时空单细胞:文章同时符合时空、单细胞的条件
时间范围:指文献出版日期,按照时间范围筛选。默认选择昨天至当天。
期刊:指文献发表的期刊,需精准查询。
物种:Genpilot根据文献提取出的物种信息,支持模糊查询,输入内容的语言需与语言选择一致,如:语言选择英文,该字段必须输入英文,否则无法查找到信息
组织:Genpilot根据文献提取出的组织部位信息,支持模糊查询,输入内容的语言需与语言选择一致,如:语言选择英文,该字段必须输入英文,否则无法查找到信息。
疾病:Genpilot根据文献提取出的疾病信息,支持模糊查询,输入内容的语言需与语言选择一致,如:语言选择英文,该字段必须输入英文,否则无法查找到信息。
IF:按文献的影响因子范围筛选,为空默认无限制。
(2)查询
根据条件查询文献,查询结果展示在下方表格。
若文章有全文信息,单击文章标题可进入文献速读,详见文献速读模块。
(3)导出
在文献表格中选择文献进行下载,支持导出excel以及word。
(4)订阅设置
将条件设置为订阅,首页将按照用户设置的订阅条件展示10篇IF最高的文献标题、期刊信息。
(5)文献字段筛选
可自定义筛选文献表格展示的字段:

(6)文献排序
文献表格可按照文章标题、发表日期、影响因子升序或者降序展示:

【优化】文献助手问答效果优化
文献助手在华大时空文献库基础上,增加检索PubMed和Goolge Scholar,加强问答效果和准确性:

留意:因检索逻辑变更,此版本文献助手暂不展示参考文献表格。
【优化】生物学解读知识图谱效果优化
知识图谱新增展示实体间的关联关系,并支持筛选实体类型:

(1)知识图谱:
提取用户问题中涉及的生物学实体,并展示其关联关系。
若实体信息未收录到时空知识库,则不展示知识图谱。
当前仅支持查看各实体的一级关联实体。
(2)实体说明:
可切换查看各实体的说明,实体说明内容目前均以英文展示。
释义:实体定义及同义词解释,多个同义词用”|“隔开。
实体关系表格:实体及关联实体的关联关系说明,最多将展示15中实体类型,对应颜色如下:

【优化】文献速读支持编辑选中的文字
文献速读功能,选择文献文字后问题输入栏上方弹出内容可进行编辑,Genpilot将基于编辑后的内容回答用户问题:

公共库
【新增】公共数据模块
公共数据中的数据是官方收录常用可公开的数据,例如时空和单细胞参考基因组(REF),用户可在公共数据中搜索及查看这些数据,如需要,则可复制到个人项目使用。
公共数据入口
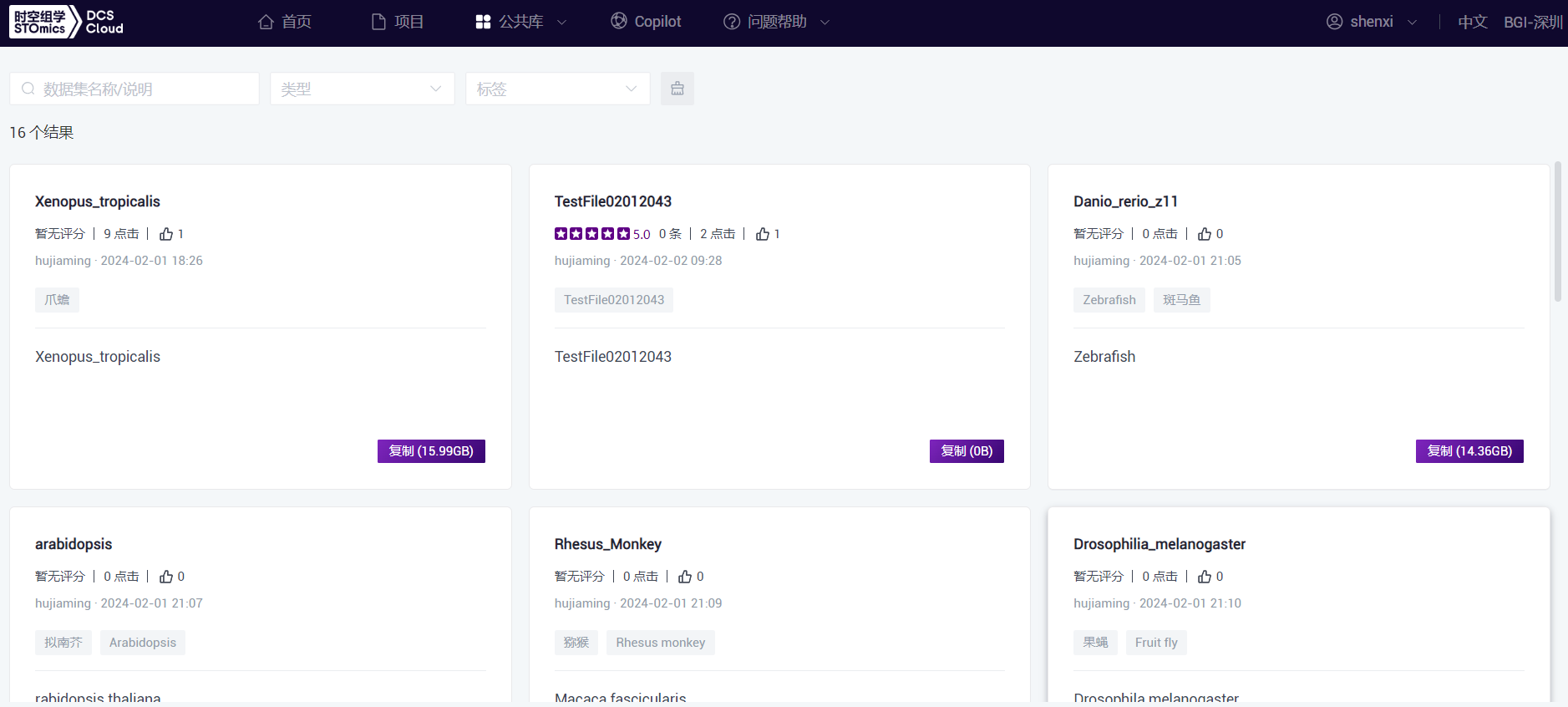
在公共库→公共数据,顶部是搜索条件,可按名称和说明、类型、标签快速过滤。
列表卡片展示的是公共数据,包含:数据名称、评论、点击量、点赞、发布人和发布时间、数据标签、数据说明,以及复制。
复制到项目
点击复制会弹出选择复制到项目窗口,选择项目和需要复制的文件夹,即可秒级复制到项目的数据管理的文件夹下,如下图:

除了列表可以直接复制公共数据到个人项目,在数据集详情页可以复制。下面看看公共数据详情页。
公共数据详情
从公共数据列表点击数据名称即可进入数据详情页,如下图:
公共数据详情页包含数据集名称、评论、点击量、评论、发布人、发布时间。
选择右边的版本,数据文件可能会有所不同,不同的版本会有对应的版本说明,选择版本后,点击复制即可弹出复制到项目窗口,选择项目和文件夹后,公共数据中的数据文件会被复制到个人项目中的数据管理下的文件夹。
如点击复制按钮旁的...按钮则可以复制当前页面 URL,以便在其它地方引用。
公共数据详情页还包含了详细信息,描述这个公共数据的来源、用途、和免责声明。
另外还包含公共数据具体的数据文件列表,每个文件的类型和大小。
最后是该公共数据的评论。
【新增】公共应用/镜像片区同步
深圳/重庆/阿里云片区内,所有公共应用/公共镜像均保持同步。
注:发布成功后,片区间文件传输需要一定时间,会导致同步存在延迟,属正常现象。
【优化】支持从复制记录页面跳转项目首页
复制记录中的项目名称支持点击跳转至该项目首页。
